Guides for Prompt Engineering, Using GPT-3 to Extract Data from Tables

What blew my mind this week
I came across this book that teaches you how to create incredible images with DALL.E 2. DALL.E 2 with all of its astonishing power is still very tricky to get to produce what you exactly want. It was trained with over 600 million image/caption pairs and learned to inherit complex patterns. There’s absolutely no way anyone can peer under the hood and decipher the exact patterns DALL.E 2 has learned!
This is why prompt engineering is more art than science.
A prompt is a relatively short snippet of text that describes exactly what you want DALLE.2 or any other LLM to do. Choose your words correctly and you can even get language models to solve problems or create beautiful images.
What I loved about this book is that it broke up image generation via prompt design into several different fundamental aspects of images such as vibes, lighting, and even 3D textured illustrations.



As far as I know, this is probably one of the most in-depth and digestible guides for prompt engineering applied to a specific domain and task. My prediction is we will see such LLM prompt design guides for solving NLP problems in text-heavy domains such as law, medicine, and banking. Like a textbook of solutions for a variety of use cases.
Use Case of the Week - Extracting Data from Tables
I came across an interesting issue where the API I built at NLP Labs was struggling to answer questions for a company’s help desk article. Digging into the issue I realized that the source text containing the relevant information was inside of an HTML table and I had a function that cleaned incoming text data before it was indexed by our semantic search models. The table HTML was getting removed!
In building NLP pipelines there’s usually a text cleaning and preprocessing step that normalizes words to lower case, trims extra whitespace, and often strips tags such as HTML/XML tags.
But in the case of table HTML, it’s important to preserve it because it actually defines a dependency between the words in a text string that a model like GPT-3 can take advantage of to extract information from it. By removing that HTML I had removed the dependencies and so the model wasn’t able to return an answer. Here’s an example table.
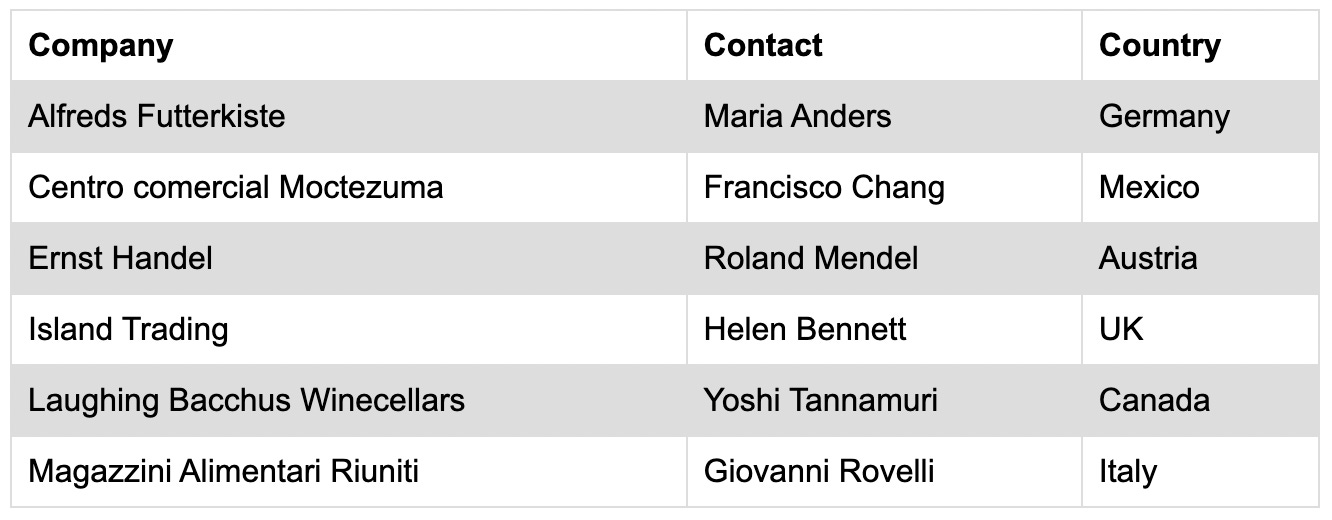
If I feed GPT-3 the tabular data with HTML tags preserved it will be able to answer the questions correctly!

My takeaways from this experience:
Sometimes in NLP there’s a signal surrounding the core words that might appear to be noisy text. so be very careful not to throw that away during preprocessing
GPT-3 still never ceases to amaze me.