Language Models and Interoperability, Enterprise Search

Tweet of the Week

Whenever Patrick McKenzie tweets or writes, I pay attention. But this tweet in particular really caught my attention. The backbone of business system software usually involves Service B reading from database A and inserting the results into database B. Sometimes both databases A and B have convenient and easy-to-use service APIs to facilitate the flow of information, but usually, there isn’t prebuilt interoperability and therefore many messy SQL queries need to be written.
I haven’t fully thought through the use case Patrick McKenzie outlines but my interpretation of his thread is that natural language itself can serve as the easy-to-use REST API. Databases A and B each have their own language models that convert incoming natural language queries and the given SQL table schemas to correct and executable SQL queries.
This would be amazing and I’m sure there are a ton of edge cases that would have to be accounted for. However, if one database could ask for the other database’s schema first then it could have all the information necessary to turn a natural query into a SQL query.
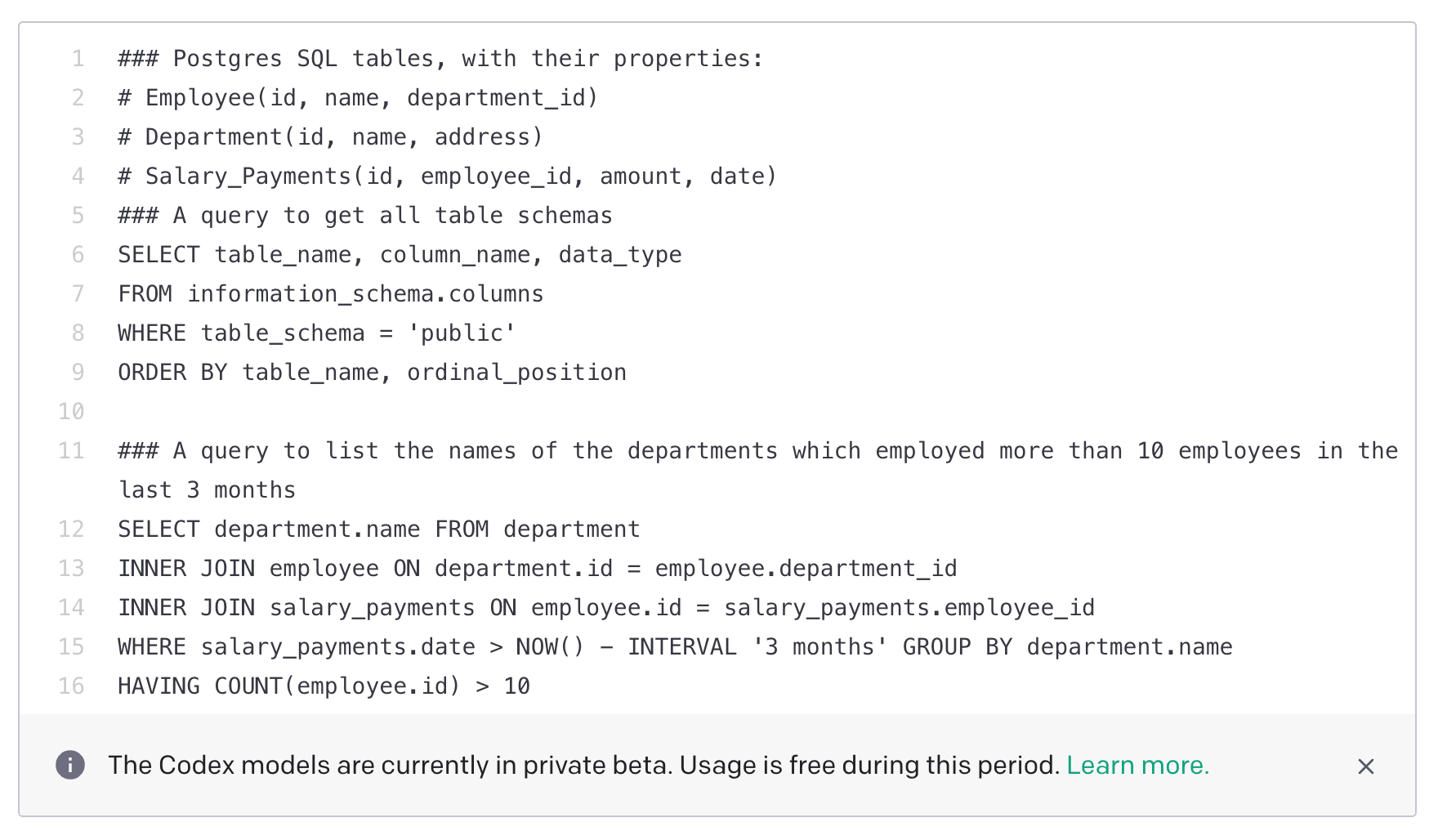
Here’s a screenshot of Codex handling natural language queries for table schema and names of departments with more than 10 employees in the last 3 months.
Use Case of the Week: Enterprise Search
We’ve all been there at some point in our careers where we’re staring at a 100-page PDF document trying to search with Ctrl-F or trying to retrieve some knowledge that could be written in one of the thousands of Notion pages. These enterprise search problems often boil down to finding a specific piece of text in one or more company documents. Depending on how often you’re manually extracting content from documents, this is either a nice to have or could make you 100x more productive.
Thanks to advances in semantic search technology, it’s now possible to index the actual contents of company documents in such a way that you can literally ask a specific question and get back the paragraph containing the answer from a pool of millions of lines of text.
What would you do with that capability?
On the top of my head:
Better PDF search without having to remember the exact keywords
Automate tedious work and focus on building better relationships with customers
Research any company knowledge about a topic and raise the baseline know-how of your entire team
Triaging which documents to review