

Problem Solving with GPT-3, Customizing Semantic Search

Favorite Tweet of the Week



How can we overcome the limitation of language models through clever prompt design? GPT-3 was built to see language in terms of “tokens” or character chunks instead of individual characters or words. The author of the tweet shows how GPT-3 struggles to do something as simple as reversing a word (top tweet) and then proceeds to literally write out an algorithm in plain English (bottom tweet) that allows GPT-3 to reverse words successfully!
The takeaway isn’t that we’ll be using Large Language Models like GPT-3 to reverse words, but rather there’s a lot of room for creativity and algorithmic thinking in getting LLMs to solve problems similar to writing code. But the key difference is LLMs enable creativity and problem solving with plain English, and I believe this is going to greatly increase the number of programmers in the world.
What I Learned This Week
If you are in a domain with specific terminology and dense documentation such as insurance, then having a handy domain-specific semantic search model that allows you to ask questions about the documentation could be a huge productivity boost. Unfortunately customizing or fine-tuning semantic search models require a large data labeling effort. You need to come up with a lot of possible questions that would return a specific paragraph in this documentation.
These question-passage pairs require a lot of time and money to generate.
GenQ to the rescue! I came across this tutorial from the vector database company Pinecone. It highlights a method called GenQ that automatically generates these question-passage pairs!
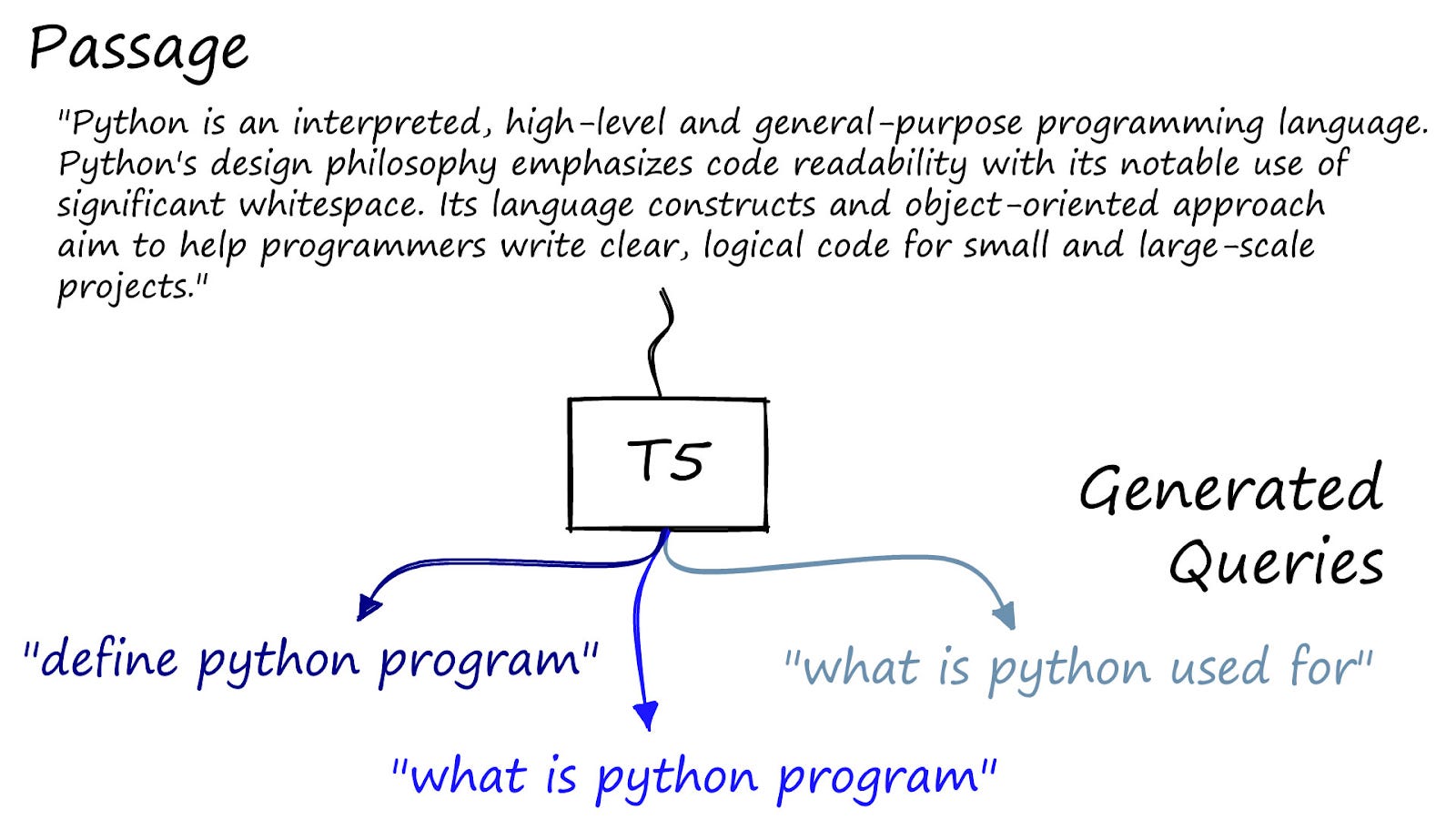
The only input required is the documents you’d want to effectively search against. The implications are huge because you could
Approach the quality of a model trained on a huge curated question-passage dataset
Customize search models at scale without spending lots of money and time